前言
随着社会的发展,人们生活水平的提高,欣赏电影逐渐成为人们闲暇时的主要娱乐方式之一。随着电影在众人的娱乐生活中占据越来越重要的地位,传统手动售票方式繁琐,统计帐户的时候一张一张的记录进入到账户薄里面,容易出现错误,所以研究一个电影售票系统已经非常的重要了。设计电影院售票系统,能方便的订票,极大的提高了了工作效率。传统的电影售票都是人工服务,观看座位都是人工安排,无法体现人性化选择,加上现在人们的生活节奏越来越快,购票时间需要相应缩短以及方便电影院工作人员的管理,本系统就是为了解决这一系列问题提出的。
电影成为现今社会人们娱乐的重要项目,因此一个完善的影院售票系统为我们的出行和观影提供了方便,避免迟到错过影片和排队拥挤。人工售票的手续繁琐、效率低下给具有强烈时间观念的管理人员带来了诸多不便,影院缺少一套完善的售票系统软件,为了对售票的管理方便,因此必须开发影院售票系统。随着计算机技术的不断应用和提高,计算机已经深入到社会生活的各个角落。而采用手工售票的方法,不仅效率低、易出错、手续繁琐,而且耗费大量的人力。为了满足售票人员对售票进行高效的管理,在工作人员具备一定的计算机操作能力的前提下,特编此影院售票系统软件以提高影院的管理效率。根据对周边电影院售票系统的调查和了解,通过系统的设计,实现电影购票系统。
1、设计任务
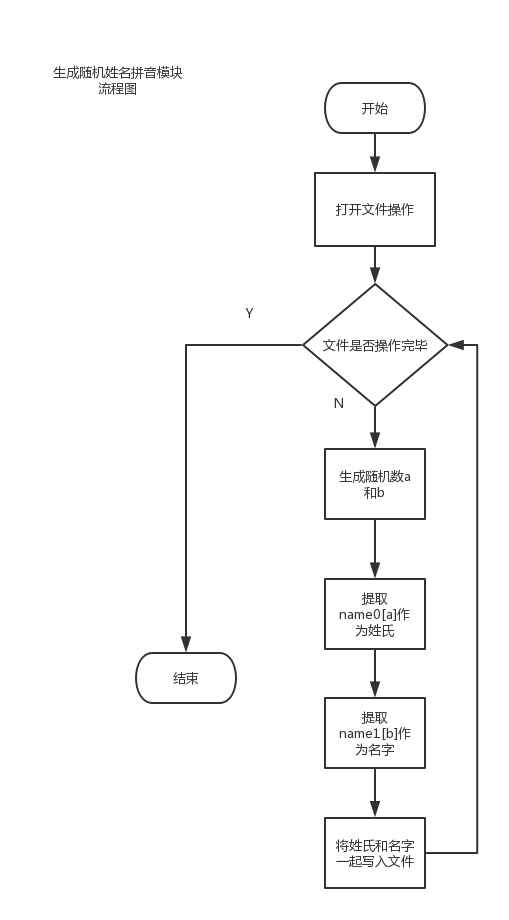
利用计算机进行电影院座位管理系统设计,能够通过数据库获得每个放映厅的售票情况,而且还可以利用计算机进行购票,已经售出的座位将不能再选。
1.1任务设计要求
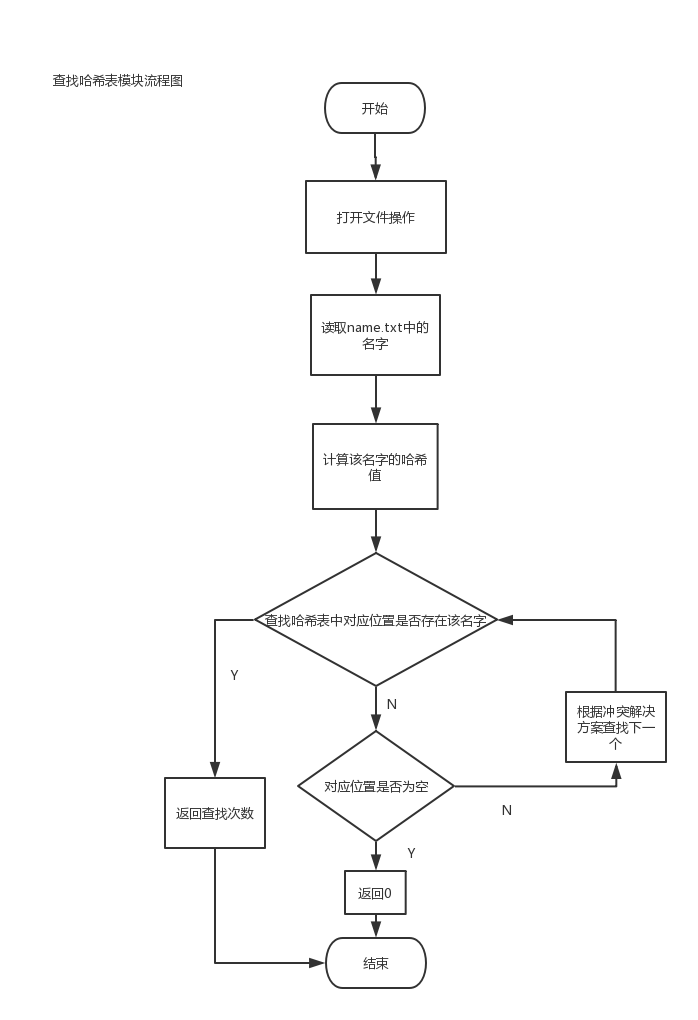
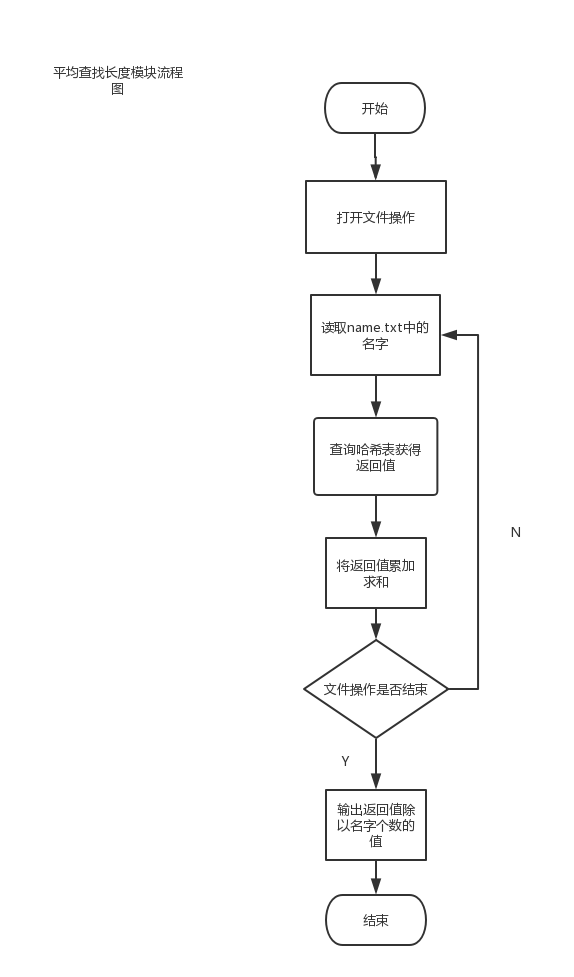
设计一个电影院座位管理系统。一个电影院有多个放映厅,每个放映厅的座位数量大于100且分多行,根据电影票的不同选择不同的放映厅,然后在相应的放映厅中选择座位,座位示意图应该与实际的方位和数量相同,已经选过的座位不能再选。
1.2系统功能需求分析
流程图:
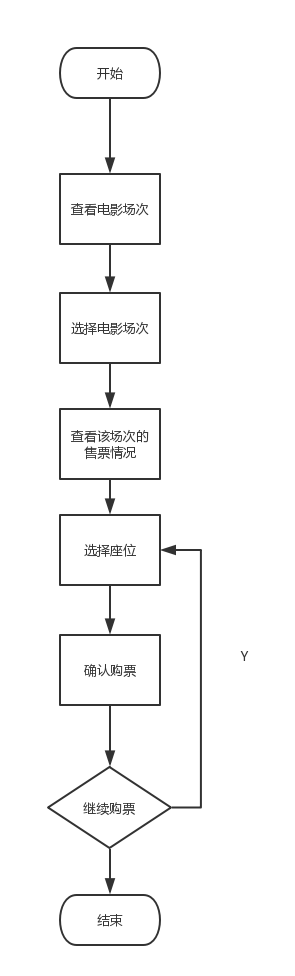
图1.21
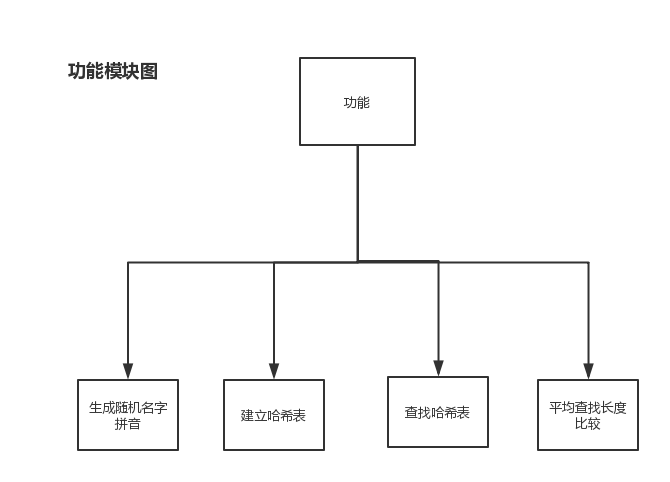
电影院座位管理系统应包含以下几个功能:
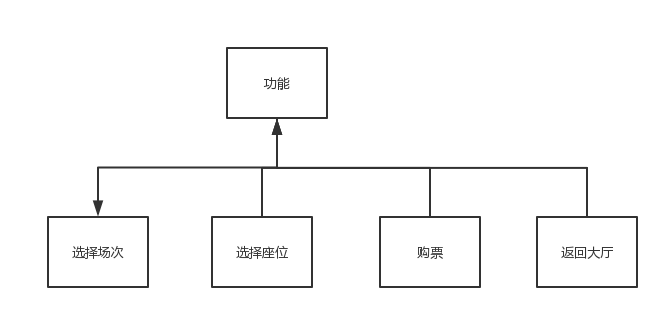
图1.22
2、总体设计
2.1开发环境
操作系统:Microsoft Windows 10 64位
IDE:CodeBlocks 32位
编译器:GNU GCC Compiler
数据库:Sqlite3
编程语言:C/C++
图形库:ACLLib
2.2 SQLite
SQLite是一款轻型的本地文件数据库,是遵守ACID的关联式数据库管理系统。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它的功能强、速度快,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等主流的操作系统,同时能够跟很多程序语言相结合。
2.21 SQLite的数据类型
在进行数据库操作之前,有个问题需要说明,就是SQLite的数据类型,和其他的数据库不同,Sqlite支持的数据类型有他自己的特色:Typelessness(无类型)。 SQLite是无类型的,这意味着你可以保存任何类型的数据到你所想要保存的任何表的任何列中, 无论这列声明的数据类型是什么。
而大多数的数据库在数据类型上都有严格的限制,在建立表的时候,每一列都必须制定一个数据类型,只有符合该数据类型的数据可以被保存在这一列当中。而在SQLite 2.X中,数据类型这个属性只属于数据本生,而不和数据被存在哪一列有关,也就是说数据的类型并不受数据列限制(有一个例外:INTEGER PRIMARY KEY,该列只能存整型数据)。
但是当SQLite进入到3.0版本的时候,这个问题似乎又有了新的答案,SQLite的开发者开始限制这种无类型的使用,在3.0版本当中,每一列开始拥有自己的类型,并且在数据存入该列的时候,数据库会试图把数据的类型向该类型转换,然后以转换之后的类型存储。当然,如果转换被认为是不可行的,SQLite仍然会存储这个数据,就像他的前任版本一样。
举个例子,如果你企图向一个INTEGER类型的列中插入一个字符串,SQLite会检查这个字符串是否有整型数据的特征, 如果有而且可以被数据库所识别,那么该字符串会被转换成整型再保存,如果不行,则还是作为字符串存储。
诚然SQLite允许忽略数据类型, 但是仍然建议在你的Create Table语句中指定数据类型. 因为数据类型对于你和其他的程序员交流, 或者你准备换掉你的数据库引擎时能起到一个提示或帮助的作用. SQLite支持常见的数据类型, 如:
1.NULL,值是NULL
2.INTEGER,值是有符号整形,根据值的大小以1,2,3,4,6或8字节存放
3.REAL,值是浮点型值,以8字节IEEE浮点数存放
4.TEXT,值是文本字符串,使用数据库编码(UTF-8,UTF-16BE或者UTF-16LE)
5.BLOB,只是一个数据块,完全按照输入存放(即没有准换)
2.22 SQLite的5个主要的函数:
sqlite3_open(), 打开数据库
sqlite3_exec(),执行非查询的sql语句
sqlite3_prepare(),准备sql语句,执行select语句或者要使用parameter bind时,用这个函数(封装了sqlite3_exec).
sqlite3_step(),在调用sqlite3_prepare后,使用这个函数在记录集中移动。
sqlite3_close(),关闭数据库文件
2.3 SQLite Studio
SQLiteStudio是一个基于QT写的SQLite数据的可视化编辑和查看的开源软件软件,使用非常简单。进入sqlitestudio官网,下载它的已经编译可用的软件包,找到跟你系统匹配的软件包,下载到自己的电脑的指定的目录中,第一次打开,需要设置默认的软件语言,这个可视化操作软件是支持多语言的,如下图所示操作
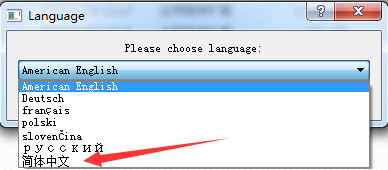
图2.31
可以可视化操作编辑我们的数据库进行增删改查操作,十分方便。
2.4建立数据库
首先创建一个数据库,在数据库中建立四张表,分别名为t1,t2,t3,t4,分别代表放映厅1,放映厅2,放映厅3,放映厅4。

图2.41
在每个放映厅的表中,只有一条string类型的数据,售票情况用0和1表示,0表示该位置已售出,1表示该位置尚未售出,如下图所示。

图2.42
2.5 数据库的操作
2.51 数据库的查询
数据库的查询SQL语句为(以放映厅1为例):SELECT * from t1,就可以查到表t1中的所有数据。
数据库的连接只需通过Sqlite3提供的C/C++接口,即可实现用户操作与数据资源的连接,并可对相关的数据库信息进行操作。
sqlite3 *db;//定义一个数据库指针
rc = sqlite3_open(“camera.db”, &db);//链接数据库
sql = “SELECT * from t1”;//把我们要执行的数据库查询SQL语句存入sql变量中
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);//执行SQL语句并调用回调函数
sqlite3_close(db);//断开与数据库的链接,释放相应的资源
2.42数据库的更新
数据库的更新SQL语句为(以放映厅1为例):UPDATE t1 set zuowei =1,就可以将表t1中的zuowei的值更新为1。
数据库的修改只需通过Sqlite3提供的C/C++接口,编辑好相应的SQL语句,即可实现用户操作与数据资源的连接,并可对相关的数据库信息进行操作。
rc = sqlite3_open(“1.db”, &db);//链接同目录下名为1.db的数据库
sql = “UPDATE t1 set zuowei = ‘123’”;//将我们的数据库更新语句赋值给变量sql1
const char* p1 = sql.data();//将string类型的sql变量赋值给const char*类型的p1
rc = sqlite3_exec(db, p1, callback0, (void*)data, &zErrMsg);//执行数据库更新语句
sqlite3_close(db);//断开与数据库的链接闭关释放相应资源。
2.5 ACLLib图形库介绍
- Acllib是一个基于Win32API的函数库,提供了相对较为简单的方式来做Windows程序。
- 实际提供了⼀个.c和两个.h,可以在MSVC和Dev C++( MinGW)等环境下中使用。
- 纯教学用途,但是编程模型和思想可以借鉴。
- 在使用ACLLib创建窗口时,我们只需要写一个Setup()函数,调用initWindow()初始化窗口,这样用户就可以定义自己所规划的窗口。同时,通过initConsole()函数,程序也打开了console,方便程序读入和反馈信息等。对于具体的程序界面设计及相应事件响应,调用相应的函数即可。
3、代码执行效果
- 编译并运行我们的程序之后,首先会显示一个黑色的命令行,接着出现我们的图形界面,有最近上映的电影可以选择,并且列出了该电影的综合评分,电影类型,电影产地以及电影时长,用户可以根据个人喜好从中选取一个电影查看座位,当用户选择任意一个电影时,会查询数据库并显示该电影的放映厅的售票情况,如下图所示:

图3.1
- 选取任意一个放映厅后,会刷新界面,显示该放映厅当前的售票情况,白色代表该位置已售出,棕色代表该位置已经售出,当我们选择一个可选的位置时,该位置会变成红色,底部有两个按钮,分别为确认选座和返回大厅,如下图所示:
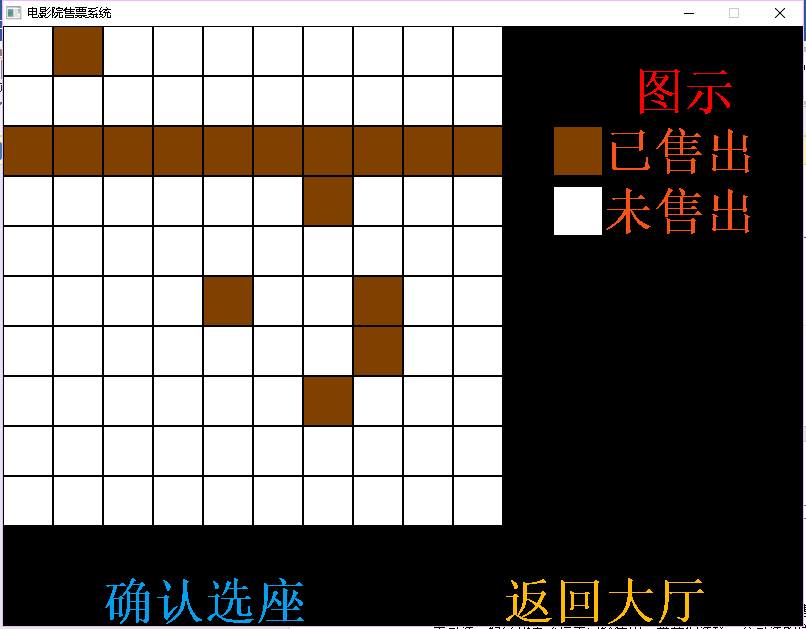
图3.2
- 当用户选择好一个可选的位置之后,点击确认选座时,如果购票成功则会弹出提示告知用户购票成功,且该位置会被锁定成棕色,且不可再被选用,同时会调用相关的代码将信息更新给数据库,以便下次再打开时能够从数据库中读取到正确的信息。

图3.3
(4)当用户点击返回大厅时,将返回上一界面,用户可以重新选择放映厅。
源代码:maplefan/cinema