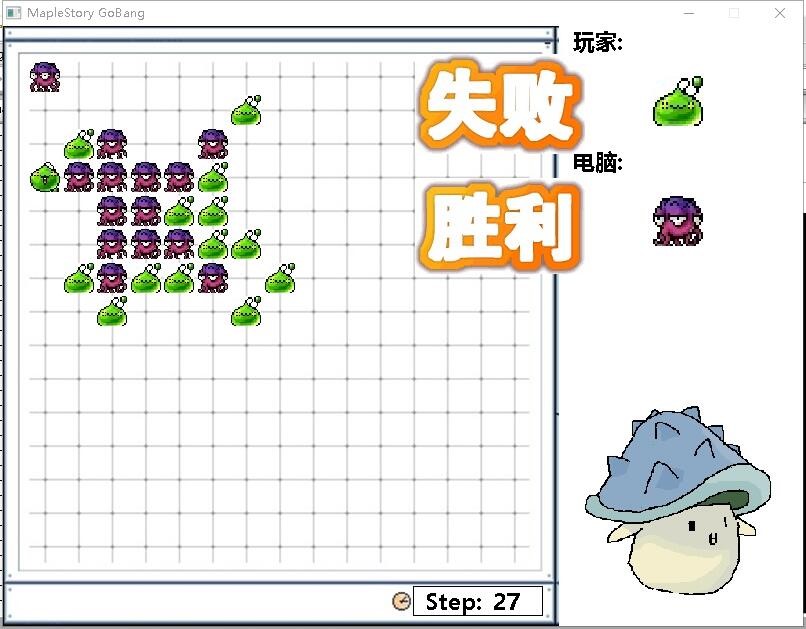
五子棋是一种两人对弈或者人机对弈的纯策略型棋类游戏,应用C语言编写程序可以在计算机上实现两人对弈和人机对弈五子棋功能。人机对弈五子棋程序由开始界面,棋盘,判断胜负和AI等子函数构成;程序中应用了数组、全局变量、图形编程等元素和语句。程序通过棋盘和棋子图像生成、玩家移子与电脑判断分数高低而落子和判断胜负等功能的实现,在Windows操作系统上用CodeBlocks实现了两人对弈和人机对弈模式。
源代码已传github:MapleStory GoBang
第一章 序 言
1.1 设计背景
五子棋相传起源于四千多年前的尧帝时期,比围棋的历史还要悠久,可能早在“尧造围棋”之前,民间就已有五子棋游戏。有关早期五子棋的文史资料与围棋有相似之处,因为古代五子棋的棋具与围棋是完全相同的。在上古的神话传说中有“女娲造人,伏羲做棋”一说,《增山海经》中记载:“休舆之山有石焉,名曰帝台之棋,五色而文状鹑卵。”李善注引三国魏邯郸淳《艺经》中曰:“棋局,纵横各十七道,合二百八十九道,白黑棋子,各一百五十枚”。这段虽没明讲是何种棋类,但至少知道远古就以漂亮的石头为棋子。因而规则简单的五子棋也可能出自当时,并是用石子作棋子。亦有传说,五子棋最初流行于少数民族地区,以后渐渐演变成围棋并在炎黄子孙后代中遍及开来。在古代,五子棋棋具虽然与围棋相类同,但是下法却是完全不同的。正如《辞海》中所言,五子棋是“棋类游戏,棋具与围棋相同,两人对局,轮流下子,先将五子连成一行者为胜”。
传统五子棋的棋具与围棋相同,棋子分为黑白两色,棋盘为15×15,棋子放置于棋盘线交叉点上。 因为传统五子棋只能实现人人对战,而用计算机编程能够实现人机对战,一个人的时候也能体验五子棋的乐趣。因此我们设计了一款拥有双人对战和人机对战的五子棋游戏。
1.2 设计目的
五子棋游戏不仅能增强人们的抽象思维能力、逻辑推理能力、空间想象力,提高人们的记忆力、心算能力等,而且深含哲理,有助于修身养性。五子棋既有现代休闲方式所特有的特征“短、平、快”,又有中国古典哲学所包含的高深学问“阴阳易理”。它既有简单易学的特点,为人民群众所喜闻乐见,又有深奥的技巧;既能组织举办群众性的比赛、活动,又能组织举办高水平的国际性比赛;它的棋文化源渊流长,具有东方的神秘和西方的直观,它是中西方文化的交融点,也是中西方文化交流的一个平台。
自从计算机作为游戏对战平台以来,各种棋类游戏如雨后春笋般纷纷冒出。五子棋是一种受大众广泛喜爱的游戏,其规则简单,变化多端,非常富有趣味性和消遣性。同时具有简单易学、既动手又动脑的特点。同时也为锻炼自己的编程能力。
第二章 需求分析
根据功能需求,将程序分为图形显示、玩家电脑走棋,胜负判断和AI判断落子位置四个函数,以下分析各模块的需求。
2.1 图形库
图形库我们使用的是ACLLib,ACLLib是一个纯教学用途的纯C语言图形库,它并非任何产业界在使用的图形库,也不会有机会发展成为流行的图形库。它只是我们为了C语言学习的目的用的非常简单的图形库。它基于MS Windows的Win32API,所以在所有的Windows版本上都能使用。但是也因此它无法做成跨平台的库在其他操作系统上使用。程序开始运行时,给出五子棋游戏名称界面,让玩家选择双人模式或者人机模式,并选择哪一方先落子。游戏开始后要求生成15×15的棋盘图像,游戏进行过程中,要求实时显示棋盘上已落下的棋子,分出胜负后,在棋盘上方显示哪一方获胜的信息。
2.2 玩家控制模块
程序开始时,需要选择游戏模式,是否让电脑先落子,才能开始游戏;游戏过程中,玩家通过鼠标点击棋盘选择落子;游戏结束时,会显示哪一方获得了胜利。
2.3 胜负判断模块
每当棋盘上多下了一颗棋子,就检测棋盘上新下的这颗棋子,一旦出现五子连线,终止游戏程序,在棋盘上方显示玩家输赢语句。
2.4电脑计分判断落子位置模块
在能下棋的空位置中,假设电脑和玩家下在此处,分别算出各个空位置的分数,并找出最大值。如果最大值是玩家下的,那么电脑就“抢”他的位置,即做到了“防守”。如果最大值是电脑下的,那就让电脑在此处下,即做到了“进攻”,如果存在多个最大值,那么简单的调用随机函数选择其中一个。
第三章 程序详细设计
3.1 开发环境
开发环境:
操作系统:Windows 10 64位
IDE:CodeBlocks 64位
编译器:GNU GCC Compiler
图形库:ACLLib
3.2 ACLLib图形库介绍及开发环境配置
详情请看ACLLib图形库初试
3.3 AI设计思路
五子棋的棋盘是15*15的大小。我的AI算法要求每一次落子之后都要去计算每一个空暇的位置的“分值”,简单的说,我们需要一个存放棋子的数组,表示是否存放了棋子,还要一个计算每一个空格的数组来记录“分数”,这个分数是后期AI用来运算的基础,也是你AI难度控制的点。
我现有的思路就是分两部分。首先是如果是玩家先落子,那么要求电脑AI随即在你落子的地方的任意一个方向,随机落子,这是第一步。接下来以后就正式进入到算法中去。
首先初始化你的分数数组,让他们全部为零。然后在每一次落子之后进行全盘的遍历,如果发现该处为空白,于是检查其四周八个方向,当然如果是边缘位置就相对修改,判断是否出了边界。若在空白处,且发现在某一对角线方向发现有一个其他颜色的棋子,那么相对的给这个空白区域的分数数组加上一定的分值,然后继续往这个方向检测是否还有连续的同一颜色的棋子,若没有则检查其他方向或者检测下一个空白位置。若是还在同一方向上面找到了相同颜色的棋子,那么第二个棋子的出现,你可以给改空白处加上双倍的分值,表明这个空白位置更加重要。依次类推,继续检测。最终AI棋子落在什么地方,依靠的是最后遍历整个分数数组,然后根据分数的高低来进行判断落子落在哪里的。
经过上一遍的遍历,每一次落子都会使得分数数组得到一些变化,每一次都会导致AI判断的变化。在这个基础上,每一次落子还要进行一次对自己本身棋子颜色的一个遍历,判断自己的情况,同时加分加在分数数组之中,这样一来,电脑就会根据自己的棋子的情况以及玩家的落子情况进行判断,哪一个地方更加适合落子。
3.4 函数说明
int isWin(int row, int col,int whoFirst);
判断当棋子下在棋盘上的(row,col)时是否分出胜负。
int Setup();
加载游戏首页的一些图片资源。
void chooseMode(void);
选择游戏的模式,有人机模式和双人模式两种。
void showIndex(void);
显示游戏首页,选择棋子种类。
void initImage1(void);
加载游戏中的一些游戏资源。
void playMusic(void);
加载游戏的背景音乐。
void mouseListener0(int x , int y ,int button ,int event);
监听鼠标,在首页时当鼠标移至指定位置时该位置的文字显示高亮,以及鼠标的点击位置。
void mouseListener1(int x , int y ,int button ,int event);
监听鼠标,在选择游戏模式界面时当鼠标移至指定位置时该位置的文字显示高亮,以及鼠标的点击位置。
void mouseListener2(int x , int y ,int button ,int event);
监听鼠标,判断人机模式下玩家的落子坐标。
void mouseListener3(int x , int y ,int button ,int event);
监听鼠标,判断双人模式下玩家的落子坐标。
char* myStrCat(char *dst,const char *src);
自己写的一个字符串处理函数,处理资源路径用。
void gameMode0(void);
人机模式。
void gameMode1(void);
双人模式。
void timerListener(int id);
定时器,用于给上一个落子地点产生闪烁提示玩家。
char * myStr(char *str,int n,int m);
自己写的一个字符串处理函数,处理资源路径用。
void Robot(int *x, int *y, int *Sum);
人机模式判断落子。
void Findscore(int *x, int *y);
查找评分最高的坐标。
void ChessOne(int *x, int *y);
玩家走第1步时的落子。
void ChessScore();
给当前棋盘没有棋子的地方打分。
第四章 游戏运行展示